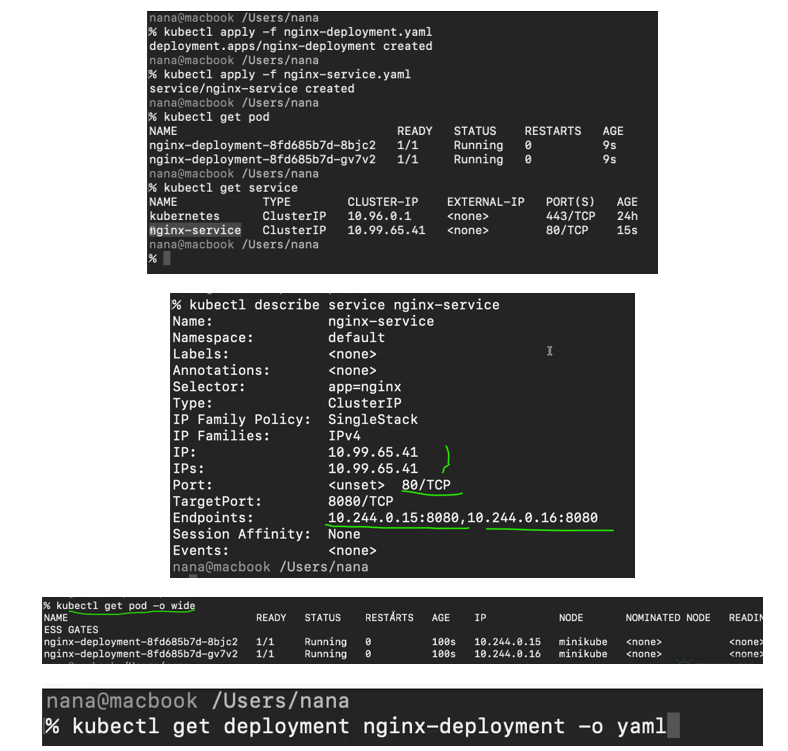
YAML Config File
Kubernetes configuration file which is the main tool for creating and configuring components in Kubernetes cluster.
Three parts of a K8s Config File:
Configuration file in Kubernetes has 3 parts the first part is where the metadata of that component . one of the metadata is obviously name of the component itself the second part in The configuration file is specification , each component File will have a specification where you put kind of configuration that you want to apply for that component. inside of the specification part obviously the attributes, will be specific to the kind of a component that we are creating. and the first 2 lines is just declaring what we want to create and version.

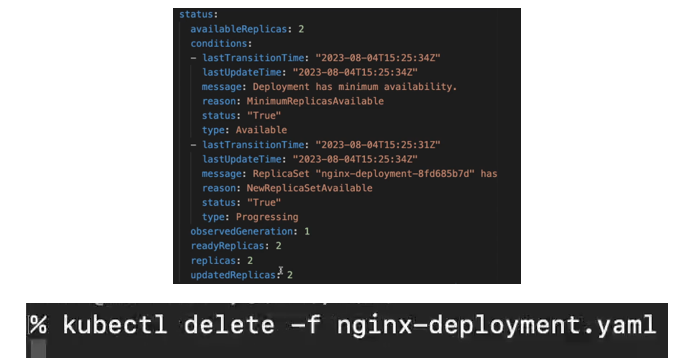
Kubernetes automatically generates and adds the status of a component by continuously comparing its desired state with the actual state. If they do not match, Kubernetes attempts to fix the issue—this is the core of its self-healing feature. For example, if we define 2 replicas for an Nginx deployment and only 1 is running, Kubernetes will detect the mismatch and create the missing replica. The status data used for this process is sourced from etcd, the control plane component that stores the cluster’s current state.
Configuration File Format: Kubernetes uses YAML, which is simple but requires strict indentation.
Storage Location:
- Usually stored with application code, as deployments and services are application-specific.
- Follows Infrastructure as Code (IaC) practices.
- Alternatively, they can be stored in a separate Git repository.
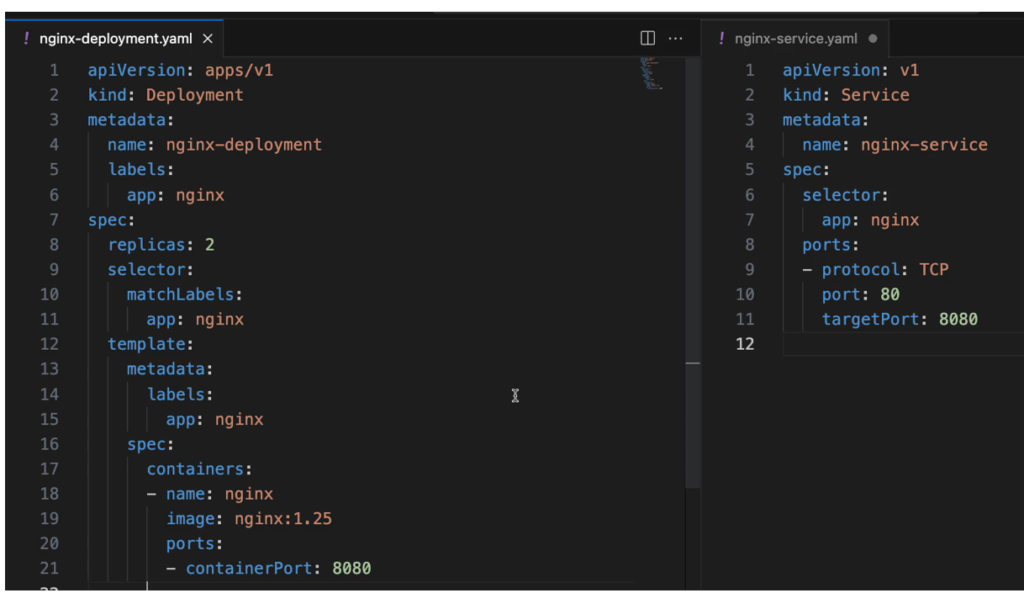
Blueprint for Pods (Template)
Deployments manage the pods beneath them, so any changes made to a deployment are automatically applied to its pods. To create pods, you create a deployment, which handles the rest. This behavior is defined in the deployment’s configuration, specifically within the template section under the spec. The template includes its own metadata and spec because it represents the pod’s configuration within the deployment’s configuration—serving as a blueprint that defines the image, ports, container name, and more.
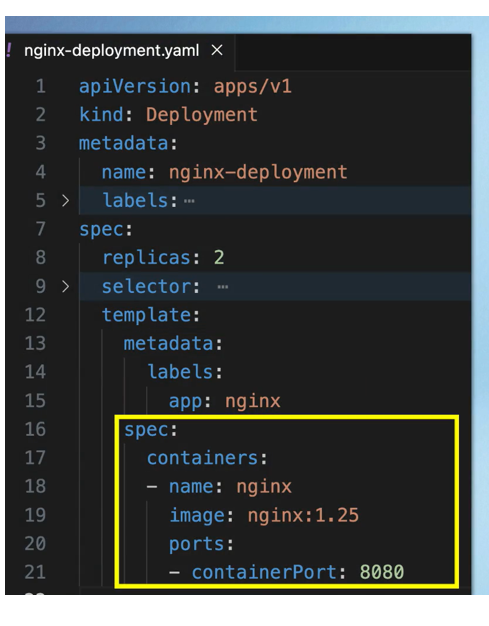
Connecting Components: (Labels & Selectors & Ports)
So, the way the connection is established is using labels and selectors , as you see metadata part contains the labels and the specification part contains selectors
Metadata Components like deployment or pod a key value pair and it could be any key value pair that you think of ex: app: nginx , that label just sticks to that component . PODs Created using this blueprint label app: nginx and we tell the deployment to connect or to match all the labels with app: nginx to create that connection So, this way deployment will know which pods belong to it. now deployment has its own label app: nginx.
And these 2 labels are used by the service selector So, in the specification of a service we define a selector which basically makes a connection between the service and the deployment or it’s pods because service must know which pods are kind of registered with it So, which pods belong to that service And that connection is made through the selector Of the label.
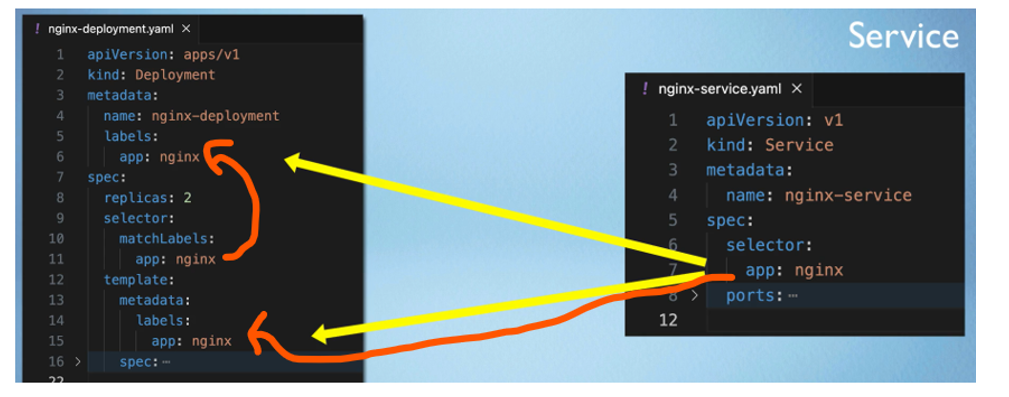
another thing that must be configured in the service and pod Is the ports I see that service has its ports configuration and the container inside of a pod is obviously running or needs to run So, me port.
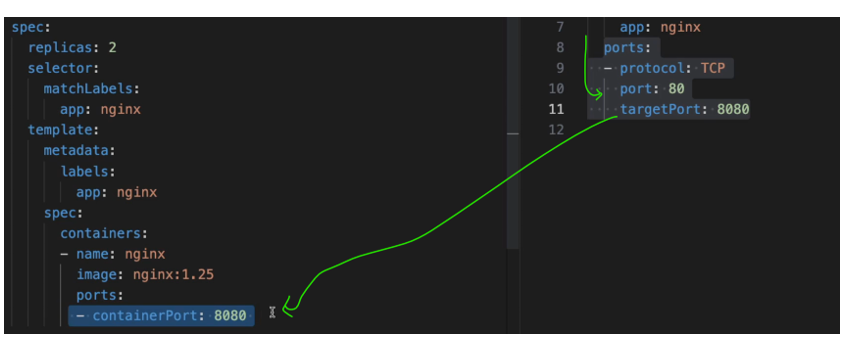
service has a port where the service itself is accessible at So, if other service sends A request to nginx service here It needs to send it on port 80 but this service needs to know to which pod it should forward the request but also, at which port is that port listening and that is the target port So, this one should match the container port and with that we have our deployment and service basic configurations done .